Adversarial Attack
An adversarial attack refers to a technique used to exploit vulnerabilities in machine learning models, particularly deep neural networks, by introducing carefully crafted input data called adversarial examples. These examples are designed to deceive the model and cause it to make incorrect predictions or classifications. The goal is to manipulate the model’s behavior in such a way that it produces a desired outcome for the attacker, while appearing indistinguishable to a human observer.
- Adversarial attacks typically involve designing attack methods specific to the target model. There is no general method that universally works for all models due to the diversity of model architectures, training processes, and defense mechanisms employed. However, there are some attack methods that can be broadly applicable across models, especially for models with similar architectures or characteristics. For example, gradient-based attacks such as the Fast Gradient Sign Method (FGSM) or the Projected Gradient Descent (PGD)
- Attackers often need to have some knowledge about the target model, such as its architecture, parameters, or access to its gradients, to craft effective adversarial examples.
Attack can also happen at training stage, e.g. data poisoning
Taxonomy
Taxonomy of Adversarial Attack Threat Model
Taxonomy of Adversarial Attack Threat Model
By Adversarial Falsification:
- False positive attacks generate a negative sample which is misclassified as a positive one (Type I Error). In an image classification task, a false positive can be an adversarial image unrecognizable to human, while DNNs predict it to a class with a high confidence score.
- False negative attacks generate a positive sample which is misclassified as a negative one (Type II Error). Also called ML evasion. This error is shown in most adversarial images, where a human can recognize the image, but the neural networks cannot identify it.
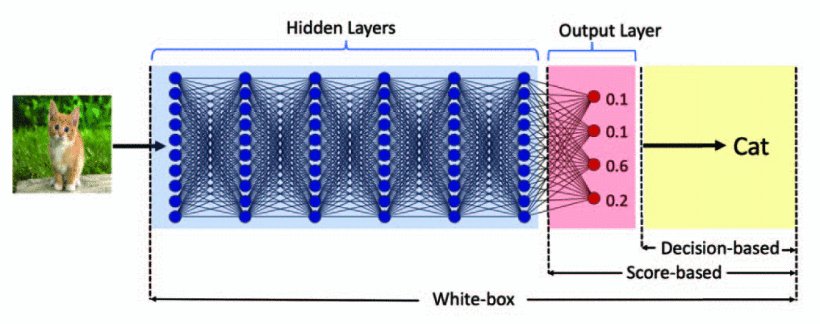
By Knowledge:
- White-box
- Black-box
Most adversarial example attacks are white-box attacks. However, they can be transferred to attack black-box services due to the transferability of adversarial examples proposed by Papernot et al.
However, it was found adversarial examples are transferrable (cf. Transferability of Adversarial Examples), hence given the same training data as the original network, an attacker can train their own mirror network of the black box original network and then attack the mirror network with white-box techniques. If attack on mirror network succeeds, it will likely succeed on the original
By Specificity: (For binary classification, targeted attacks are equivalent to nontargeted attacks.)
- Targeted attack: misguide DNNs to a specific class.
- Non-targeted attack: do not assign a specific class to the neural network output. The adversarial class of output can be arbitrary except the original one.
By Frequency:
指向原始笔记的链接
- One-time attacks take only one time to optimize the adversarial examples.
- Iterative attacks take multiple times to update the adversarial examples.
Taxonomy of Perturbation
Scope:
-
Individual attacks generate different perturbations for each clean input.
-
Universal attacks only create a universal perturbation for the whole data set. This perturbation can be applied to all clean input data.
Limitation
- optimization vs constraint
measurement
- p-norm distance:
- Psychometric perceptual adversarial similarity score (PASS)
White-Box Methods of Adversarial Attack
Fast Gradient Sign Method (FGSM)
Check Fast Gradient Sign Method (FGSM)
PGD Attack
Check Projected Gradient Descent (PGD)
Optimization-based Methods
find such that is minimized, and and .
L-BFGS
This problem can be very difficult to solve, however, so Szegedy et al. instead solve the following problem:
The original attack algorithm uses L-BFGS to solve the optimization problem.
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, et al., “Intriguing properties of neural networks”, ICLR, 2013.
Line search is performed to find the constant c>0 that yields an adversarial example of minimum distance: in other words, we repeatedly solve this optimization problem for multiple values of c, adaptively updating c using bisection search or any other method for one-dimensional optimization.
Carlini-Wagner Attack (CW)
Nicholas Carlini, David Wagner. Towards Evaluating the Robustness of Neural Networks. In: Proceedings of the IEEE Symposium on Security and Privacy (S&P 2017), San Jose, CA, USA, May 22-26, 2017: 39-57
Here is a hard constraint, and can be relaxed by selecting an objective function such that if then .
Examples of objective function:
- where is the probability of class t on input
The problem can now be formulated as:
find such that is minimized, and .
Note that the norm is problematic for optimization. We can replace it with a proxy function like , where is a bound that is decreased at every iteration.
The box constraints can be dealt with using Projected Gradient Descent (PGD).
Diffing Networks
The goal is to find a differencing input give two neural networks trained to learn the same function.
Simply: while :
Black-Box Methods of Adversarial Attack
- decision-based adversarial attack
- score-based adversarial attack