Taxonomy of Adversarial Attack Threat Model
By Adversarial Falsification:
- False positive attacks generate a negative sample which is misclassified as a positive one (Type I Error). In an image classification task, a false positive can be an adversarial image unrecognizable to human, while DNNs predict it to a class with a high confidence score.
- False negative attacks generate a positive sample which is misclassified as a negative one (Type II Error). Also called ML evasion. This error is shown in most adversarial images, where a human can recognize the image, but the neural networks cannot identify it.
By Knowledge:
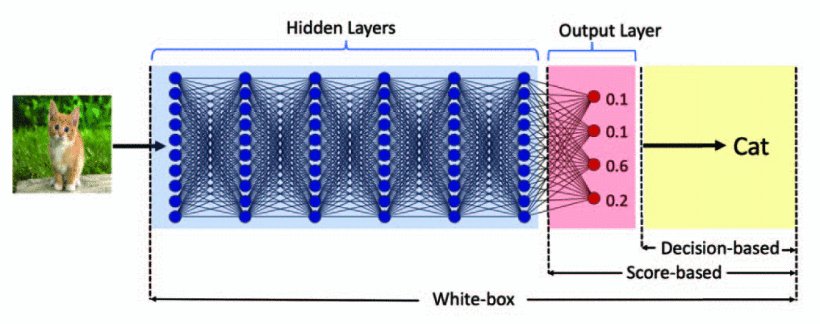
- White-box
- Black-box
Most adversarial example attacks are white-box attacks. However, they can be transferred to attack black-box services due to the transferability of adversarial examples proposed by Papernot et al.
However, it was found adversarial examples are transferrable (cf. Transferability of Adversarial Examples), hence given the same training data as the original network, an attacker can train their own mirror network of the black box original network and then attack the mirror network with white-box techniques. If attack on mirror network succeeds, it will likely succeed on the original
By Specificity: (For binary classification, targeted attacks are equivalent to nontargeted attacks.)
- Targeted attack: misguide DNNs to a specific class.
- Non-targeted attack: do not assign a specific class to the neural network output. The adversarial class of output can be arbitrary except the original one.
By Frequency:
- One-time attacks take only one time to optimize the adversarial examples.
- Iterative attacks take multiple times to update the adversarial examples.