model extraction
A model extraction attack happens when a malicious user tries to “reverse-engineer” this black-box victim model by attempting to create a local copy of it. That is, a model that replicates the performance of the victim model as closely as possible. Moreover, this stolen copy could be used as a reconnaissance step to inform later Adversarial Attack.
Difference with Knowledge Distillation
How to steal modern NLP systems with gibberish? | cleverhans-blog
There are three important differences between model extraction and distillation.
- Training Data - Distillation usually assumes access to the original training dataset or a different dataset sampled from the same distribution than the original training data’s distribution. In model extraction settings, the training data is often unknown to the attacker.
- Access to Victim Model - In model extraction, attackers have a limited access to the victim model: most of the time, they can in fact only get access to the label predicted by the model. Instead, distillation is performed with access to the model’s confidence scores for each possible output. Prior work has also shown that distillation can be improved by using intermediate hidden representations of the teacher. This requires white box access to the victim model, which is not a realistic assumption to make when stealing a model.
- Goal - Distillation aims to transfer knowledge from a big model to a small model. That is, distillation is used to decrease the number of parameters needed to store the model. This is often used as a way to support training large models on datacenters with lots of computing resources and then later deploy these models on edge devices with limited computing resources. This compression is not needed in model extraction. Instead, the adversary is primarily interested with the accuracy of the extracted model with respect to the victim model.
Note: 但实际中,模型窃取一般需要攻击者获得一个和训练集分布类似的替代数据集。如‘Knockoff Nets: Stealing Functionality of Black-Box Models’
Data-free methods
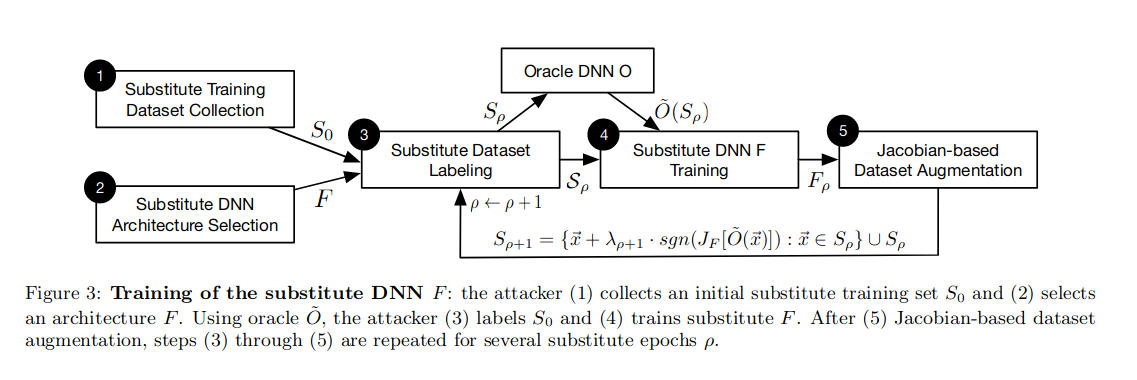
- The paper ‘Practical Black-Box Attacks against Machine Learning’ trains a substitute model for Adversarial Attack.
- Check out the paper Data-Free Learning of Student Networks from Huawei. It trains a GAN network to synthesize images that resemble the original training data, and uses these data and Knowledge Distillation to train a student network. The GAN is trained by using the teacher network as a fixed discriminator. However, since the teacher does not tell if the image if real or fake, and instead gives predicted labels, the loss function is modified accordingly.
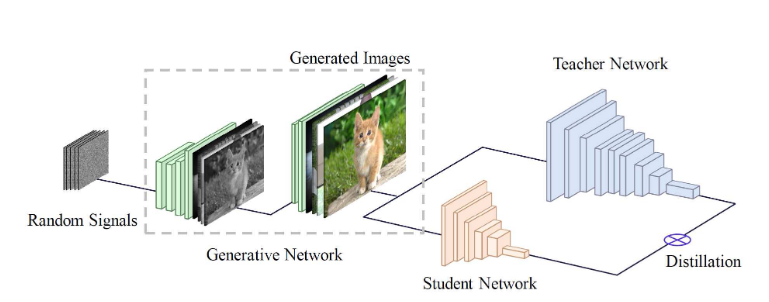 However, note the method relies heavily on image classification task.
However, note the method relies heavily on image classification task. - Similarly, the paper ‘Data-Free Model Extraction’ uses GAN architecture for model extraction.
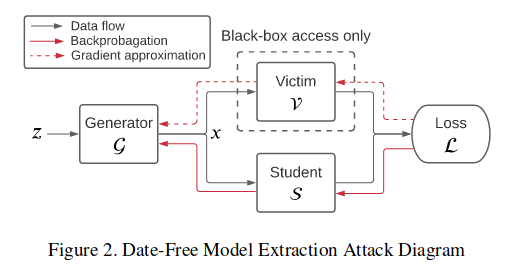 However, here the generator’s goal is to maximize the disagreement of the teacher and student networks, while the student aims to minimize it. Besides, since the gradient of teacher is not accessible, they use some gradient approximation methods.
However, here the generator’s goal is to maximize the disagreement of the teacher and student networks, while the student aims to minimize it. Besides, since the gradient of teacher is not accessible, they use some gradient approximation methods.
Defense
Watermarking
Traditionally, this method is actually similar to data poisoning, by adding a backdoor to the model (a.k.a watermark) that can be triggered later to identify the model. However, it requires the adversary to share the model they have stolen and might only apply to business.
(1) Adi, Y.; Baum, C.; Cisse, M.; Pinkas, B.; Keshet, J. Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring; 2018; pp 1615–1631.
Watermarking can also happen at the prediction stage instead of training. DAWN modifies a small fraction of responses (0.5% or less) returned by the prediction API by replacing correct labels with incorrect ones. This embeds a watermark into any surrogate model trained using the responses. It can be used later to verify if a suspected surrogate model contains the watermark and is therefore extracted from the victim model.
(1) Szyller, S.; Atli, B. G.; Marchal, S.; Asokan, N. DAWN: Dynamic Adversarial Watermarking of Neural Networks. arXiv July 16, 2021. https://doi.org/10.48550/arXiv.1906.00830.