data poisoning
What is data poisoning and how to prevent it
A poisoning attack begins when adversaries, known as “threat actors”, gain access to the training dataset. They can then poison the data by altering entries or injecting the training dataset with tampered data. And by doing so, they can achieve two things: lower the overall accuracy of the model or target the model’s integrity by adding a “backdoor” → Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning.
Here are some of the most famous cases of data poisoning attacks:
- Google’s Gmail Spam Filter1 : A few years ago, there were multiple large-scale attempts to poison Google’s Gmail spam filters. The attackers sent millions of emails intended to confuse the classifier algorithm and modify its spam classification. And this poisoning attack enabled adversaries to send malicious emails containing malware or other cybersecurity threats without the algorithm noticing them.
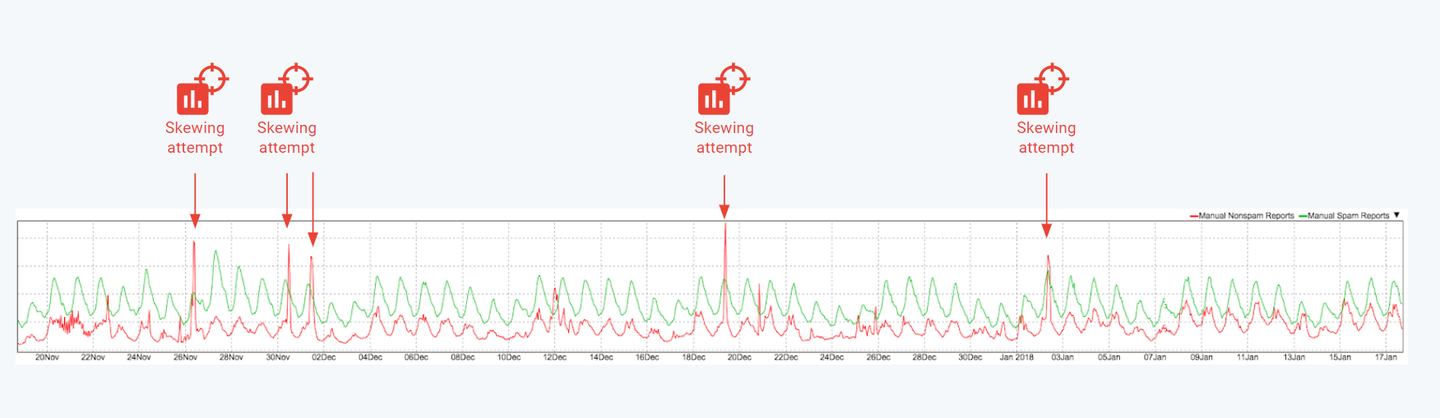
- Microsoft’s Twitter Chatbot2 : In 2016, Microsoft launched a Twitter chatbot named “Tay.” Its algorithm trained Tay to engage in Twitter discussions and learn from these interactions. However, cybercriminals saw the opportunity to taint its dataset by feeding it offensive tweets, turning the innocent chatbot hostile. Microsoft had to shut down the chatbot within hours of its launch as it started posting lewd and racist tweets.
How to Prevent:
- Ensure the integrity of the training data by obtaining it from trusted sources and validating its quality.
- Implement robust data sanitization and preprocessing techniques to remove potential vulnerabilities or biases from the training data.
- Regularly review and audit the LLM’s training data and fine-tuning procedures to detect potential issues or malicious manipulations.
- Utilize monitoring and alerting mechanisms to detect unusual behavior or performance issues in the LLM, potentially indicating training data poisoning.
Backdoor poisoning attack
Per the paper Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Input-instance-key strategies
The goal of input-instance-key strategies is to achieve a high attack success rate on a set of backdoor instances that are similar to the key k.
given Σ and k, the adversary samples n instances from Σ(k) as the poisoning instances , and construct poisoning samples to be injected into the training set.
Pattern-key strategies
Pattern-key strategies craft poisoning samples in a particular way such that this attack causes the victim model to achieve a high attack success rate on a class of backdoor instances sharing the same pattern.
The pattern can be formalized as pattern-injection function Π, a mapping of , so that Π(k, x) = x′ generates an instance x′.
- Blended Injection Strategy:
 when creating poisoning samples to be injected into the training data, a backdoor adversary may prefer a small α to reduce the chance of the key pattern to be noticed. on the other hand, when creating backdoor instances, the adversary may prefer a large α
when creating poisoning samples to be injected into the training data, a backdoor adversary may prefer a small α to reduce the chance of the key pattern to be noticed. on the other hand, when creating backdoor instances, the adversary may prefer a large α - Accessory Injection Strategy

- Blended Accessory Injection Strategy

Some practical poisoning methods against web-scale machine learning datasets
(1) Carlini, N.; Jagielski, M.; Choquette-Choo, C. A.; Paleka, D.; Pearce, W.; Anderson, H.; Terzis, A.; Thomas, K.; Tramèr, F. Poisoning Web-Scale Training Datasets Is Practical. arXiv February 20, 2023. https://doi.org/10.48550/arXiv.2302.10149.
split-view poisoning
The first attack, called split-view poisoning, takes advantage of the fact that the data seen during the time of curation could differ, significantly and arbitrarily, from the data seen during training the AI model.
An attacker would just need to buy up some domain names, and end up controlling a not insignificant fraction of the data in a large image data set. Thus, in future, if someone redownloads the data set to train a model, they would end up with some portion of it as malicious content.
front-running attack
The attacker makes short-lived edits to crowdsourced data like Wikipedia right before it is scraped for inclusion in a dataset snapshot. Even if edits are quickly reverted, the snapshot will contain the malicious version.
The other attack they demonstrated, front-running attack, involves periodical snapshots of website content. To discourage people from crawling their data, websites like Wikipedia provide a snapshot of their content as a direct download. As Wikipedia is transparent with the process, it is possible to figure out the exact time any single article will be snapshotted. “So…as an attacker, you can modify a whole bunch of Wikipedia articles before they get included in the snapshot,” Tramèr says. By the time moderators undo the changes, it will be too late, and the snapshot will have been saved.
Defense
General idea (OWASP )
How to Prevent:
- Ensure the integrity of the training data by obtaining it from trusted sources and validating its quality.
- Implement robust data sanitization and preprocessing techniques to remove potential vulnerabilities or biases from the training data.
- Regularly review and audit the LLM’s training data and fine-tuning procedures to detect potential issues or malicious manipulations.
- Utilize monitoring and alerting mechanisms to detect unusual behavior or performance issues in the LLM, potentially indicating training data poisoning.)
Other papers
- Poisoning attacks against support vector machines (2012): Introduced dataset poisoning attacks and analyzed vulnerabilities.
- See also: